Not because they were wrong. Not because the team failed to execute. Because the gap between strategy approved and value realized is filled with a thousand small decisions that no one tracked, no one owned, and no one signed for. The plan landed in a deck. The deck landed in a quarterly review. The review landed in a folder. The value never landed anywhere.
This is the realization gap. And it is the single largest source of wasted IT, analytics, and transformation spend in the modern enterprise.
Deliver Real Value is the second book in the BRM Accelerator Series, and it picks up exactly where Earn Strategic Trust leaves off. Earn Strategic Trust builds the relationship foundation. Deliver Real Value builds the execution muscle. Together they describe the two halves of the modern BRM role — and neither half is enough on its own.
The book is built around one core argument: in a world where AI compresses advisory work and finance demands realized numbers, the BRMs and digital leaders who survive are the ones who can carry an initiative end-to-end through realization, not just frame it well at the start.
Inside, you will find a framework for closing the realization gap on every initiative you touch. You will find the difference between owning a roadmap and owning an outcome, and why the second is the only one that compounds. You will find the discipline of killing initiatives whose value model does not hold up, before they consume more budget. You will find the practice of signing the value case in your own name and the operational consequences of doing it.
This is a book about execution accountability in an era when AI can produce strategy faster than humans can review it. The strategic framing is now commodity. The realized outcome is the moat. If you have ever delivered a flawless project that somehow still failed to move the business, this book explains why and how to fix it.
Strategy without realization is theater. Deliver Real Value is the playbook for ending the theater and starting the work that actually moves the line.
The second book in the BRM Accelerator Series. For BRMs, product owners, and digital leaders who need their work to convert into realized business outcomes — not just well-framed strategies.
The most dangerous moment in an IT leader’s career is the moment they think they are the strategic partner.
The title says it. The org chart says it. HR says it. But sit in the actual strategy meeting and notice who speaks first, whose opinion the CEO defers to, who gets pulled into the room before the slide deck is built. If that person is not you, the title is decorative.
Strategic trust is not assigned. It is earned. And it is earned in a very specific way that almost no one teaches.
Earn Strategic Trust is the first book in the BRM Accelerator Series, and it is the foundation everything else in my work stands on. The premise is simple: there is a five-stage path from being an order taker to being a true strategic partner, and most BRMs, IT leaders, and digital executives are stuck somewhere in stage two without knowing it.
The book maps the path. It names the behaviors that move you up the ladder and the ones that hold you back. It dismantles the comfortable myth that strategic trust accumulates from doing good work over time. It does not. Strategic trust is built by specific decisions made under specific conditions — the way you frame a tradeoff, the way you handle a missed commitment, the way you tell an executive something they do not want to hear.
Inside, you will find the five archetypes of the BRM journey and how to identify which one your business partners see you as today. You will find the language patterns that signal advisory authority and the ones that signal subordination. You will find a framework for building executive credibility deliberately rather than hoping it accumulates. You will find the moments — the small, repeated, high-leverage moments — where strategic trust is actually won or lost.
This is not a leadership book. It is a practitioner’s playbook for the role that sits between IT and the business, the role that is harder than either job alone because it requires fluency in both. If you have ever felt like you were one good quarter away from being treated as a peer to the executives you serve, this book is the bridge.
The work matters less than how the work is received. Earn Strategic Trust shows you how to engineer the reception.
The first book in the BRM Accelerator Series. For BRMs, IT leaders, product owners, and digital executives who are tired of being one rung below the table where the real decisions get made.
Most IT investments fail the same way. Not in execution. In math.
A team ships a platform on time, under budget, with high adoption. The CFO asks one question at the next review: “What was the realized value?” The room goes quiet. Someone produces a slide with adoption metrics and user satisfaction scores. The CFO nods politely. The next funding cycle, that team’s budget gets cut.
This is not a delivery problem. It is a quantification problem.
For fifteen years I watched senior IT leaders, BRMs, and analytics directors build extraordinary capabilities that disappeared from the executive narrative within twelve months. The work was real. The value was real. But the number — the specific, defensible, dollar-attached figure that ties the work to a business outcome — was missing. And in an era where finance, procurement, and the board read everything through ROI, missing the number means missing the seat at the table.
Quantify Your Impact is the methodology I built across two decades of pressure-testing what actually defends an IT investment to a CFO who has never seen the platform. It is not a theory book. It is a field manual.
Inside, you will find the Quantified Impact Framework — a ten-step methodology for converting any IT, analytics, or digital initiative into a defensible value case. You will find the seven-field business value schema that finance, audit, and the board accept without rework. You will find the difference between projected value and realized value, and why most leaders confuse the two until the moment it costs them. You will find a step-by-step process for building a 3-year quantified projection that survives executive scrutiny.
This is the book I wish I had when I first sat in a budget review and could not defend a $4M investment with a number. By the end of the next chapter, you will be able to.
The work has shipped. The question is whether anyone outside your team can see it. Quantify Your Impact gives you the language, the math, and the playbook to make sure they can.
If you have ever been told your impact “speaks for itself” — and then watched it not speak loud enough — this book is for you.
A practical guide for IT leaders, BRMs, product owners, and analytics directors who need their work to land in the executive narrative. Part of the BRM Accelerator Series.
Are you doing a lot of proof of concepts, or you’re trying to figure out different ways to optimize your infrastructure and decrease costs?
Hi, I’m Peter Nichol, Data Science CIO. Allow me to share some insights.
What is hyper-converged infrastructure?
Today, we’re going to talk about hyper-converged infrastructure, also known as HCI, what it can do, and the potential benefits.
HCI is a term that I came across over the last couple of weeks. I was curious to get more involved in exactly what it was and its capabilities related to data analytics. I envisioned appliances and other technologies with built-in processors like IBM Netezza (a data warehouse appliance) and others. I was interested in what precisely this hyper-converged infrastructure could potentially achieve.
Hyper-converged infrastructure combines compute storage and networking into a single, virtualized environment. This technology takes advanced compute, RAM, and storage which you’re already familiar with. These are all elements of a hyper-converged infrastructure. You can dynamically configure and allocate compute, RAM-based, and set up different networking configurations based on your needs, all within a single unit.
This single virtualized system uses a software-defined approach to leverage dynamic pools of storage, replacing dedicated hardware.
The benefits of hyper-converged infrastructure?
First, there is less risk of vendor lock-in. The rationale is that you’re not as susceptible to vendor lock-in because you have an easily swapped-out appliance. Second, HCI solutions offer public cloud agility with the control that you probably want from a solution hosted on-prem. Third, considering the total lifetime costs, running an HCI environment doesn’t cost that much because you have compute and storage and networking combined in a single unit.
Hyperconverged storage platforms players
Like many industrial markets, we have large players that control a considerable percentage of this hyper-converged storage platform market. These are the major industry players. Of course, there are hundreds of more niche players, but these staples provide a good starting point to understand the capabilities offered.
Major hardware players
HPE/SimpliVity
Dell EMC
Nutanix
Pivot3
Major software players
VMware (vSAN)
Maxta
HPE, Nutanix, and Pivot3 provide a single virtualized environment that can be leveraged almost out-of-the-box. And when you think about how these really can be optimized, let me give you a couple of different use cases where these are most efficient.
High throughput analytics: When your business requires high compute capabilities and demand faster compute processing, this type of integrated solution offers many possibilities. Typically, this business case is best applied when heavy data processing needs can benefit from having the storage and compute very close together. This can be a significant advantage for the end-users perception of application and visualization performance.
Virtualized desktops: Running virtualized desktop often requires a wide range of scalability. Over the weekend, for example, you might run 25% of your normal nodes, whereas, during the week, you might have peak times where you’re running 125% of the average weekly for computing. Based on the number of users and volume of workgroups your enterprise supports, the ability to rapidly scale up and down can be advantageous.
COTS specifications for performance: much larger out-of-the-box solutions, like SAP or Oracle, typically have pre-determined specifications in terms of computing, storage, and networking that are required to run the environment to performance standards. Using HCI type of environments is a great way to ensure the setup needed for optimal performance. Once the standard specifications are known, you can scale your hyper-converged infrastructure directly to those needs or overbuild to ensure you’ll hit or exceed performance targets/
What’s in the market today for HCI?
There are hundreds of products that offer similar but not the same functionality. Therefore, it’s essential to consider how each technology component extends existing capabilities before adding technology into an already complex ecosystem. All too often, leaders end up adding technologies because they are best-in-class and end up duplicating technologies in their architecture stack that perform near-identical functions.
Nutanix Acropolis has five key components that make it a complete solution for delivering any infrastructure service:
StarWind is the pioneer of hyper-convergence and storage virtualization, offering customizable SDS and turnkey (software+hardware) solutions to optimize underlying storage capacity use, ensure fault tolerance, achieve IT infrastructure resilience and increase customer ROI.
VxRail, As the only fully integrated, preconfigured, and pre-tested VMware hyper-converged infrastructure appliance family on the market, VxRail dramatically simplifies IT operations, accelerates time to market, and delivers incredible return on investment.
VMware vSAN is a software-defined, enterprise storage solution powering industry-leading hyper-converged infrastructure systems.
IBM CS821/CS822: IBM Hyperconverged Systems powered by Nutanix is a hyper-converged infrastructure (HCI) solution that combines Nutanix Enterprise Cloud Platform software with IBM Power Systems.
Cisco HyperFlex: Cisco HyperFlex. Extending the simplicity of hyper-convergence from core to edge and multi-cloud.
Azure Stack HCI: The Azure Stack is a portfolio of products that extend Azure services and capabilities to your environment of choice—from the data center to edge locations and remote offices. The portfolio enables hybrid and edge computing applications to be built, deployed, and run consistently across location boundaries, providing choice and flexibility to address your diverse workloads.
Huawei FusionCube BigData Machine is a hardware platform that accelerates the Big Data business and seamlessly connects with mainstream Big Data platforms. The BigData Machine provides the high-density data storage solution and Spark real-time analysis acceleration solution based on Huawei’s innovative acceleration technologies.
Each of these technologies adds something specific in terms of functionality and capability extension. Consider which products are already part of your infrastructure and integrate well with potential new technology additions.
Advantages to running an HCI
Hyper-converged infrastructure can offer companies huge benefits and aren’t all associated with pure performance gains.
First, when using hyper-converged infrastructure, you don’t need as many resources to maintain and support the environment. Second, an HCI environment is less complex and more simplified; this removes the conventional layers of microservices that commonly require technical specialization. Third, by eliminating the need for technology resource specialization, maintenance, support, and enhancement resources decrease, adding to cost savings.
Second, there is a financial benefit by having the compute and storage very close together. Almost always, of course, depends on the specific business case; there will be cost-saving realized from this coupled architecture.
Third, major business transformations can be more easily supported. For example, let’s assume that the business pivots and traffic increases by 40%. Usually, this would be beyond what would be generally supported for elastic growth, and therefore there would be a performance hit. However, because this technology is plug-and-play, it’s easy to swap out an existing appliance for a newer appliance with improved capabilities. Of course, these applications can auto-scale up to a limit, but swapping out appliances is a viable option if that limit is hit.
As you consider starting up proof of concepts (POCs) and exploring different ways to provide value to your business customers, evaluating hyper-converged technologies and infrastructures might be a safe way to ensure that performance guarantees are achieved.
Is there a business case for in-storage data processing? Of course, there is, and I’m going to explain why.
Hi, I’m Peter Nichol, Data Science CIO.
Computational storage is one of those terms that’s taken off in recent years that few truly understand.
The intent of computational storage
Computational storage is all about hardware-accelerated processing and programmable computational storage. The general concept is to more data and computers closer together. The idea is that when your data is far away from your compute, it not only takes longer to process, but it’s more expensive. This scenario is common in multi-cloud environments where moving and erasing data out is a requirement, but that requirement comes at a very high cost. So the closer we can move that data to our compute power, the cheaper it will be, and ultimately, the faster we will be able to execute calculations.
Business cases for computational storage
The easier way to understand computation storage is to observe a few examples. These concepts are primarily embedded in startups and are most commonly known as “in-situ processing” or “computational storage.”
First, let’s focus on an example around hyperscalers. Hyperscale is used to do things like AI compute, high throughput video processing, and even composable networking. When we observe organizations like Microsoft, they are incorporating these technologies into their product suites. For example, Microsoft is using computation storage in their search engines with the application of use field-programmable gate arrays (FPGAs). The accelerated hardware enables search engines and can provide those credentials and analytical results in less than microseconds. Also, these capabilities are expanding into other capabilities like Hadoop MapReduce using DataNodes for storage and processing.
Second, architectures that are highly distributed are very effective. Hyperscale architectures build a great foundation to scale computational compute capabilities. The concept of segmenting hardware to software is not new. Even AWS Lambda—typically a data streaming capability—we can deconstruct an application to break out data flow into several parts. This makes managing multiple data streams much more streamlined. For example, data feeds can be individually ingested into a data stream, then AWS Lambda can manage the data funnel from AWS Lambda into computational storage. Once that stream is fed into computational storage, that data stream is more efficient and capable of executing instruction even faster than if not fed into computational storage.
Why look at computational storage now?
Do we as leaders even care about computational compute? Yes, we do. Here’s why.
Looking over the last year or even the previous decade, the way data is stored is designed and architected based on how CPUs are designed to process that data. That was great when the hardware designs aligned to the way data was processed. But, unfortunately, how CPUs were designed and architected over the last ten years has dramatically changed. And as a result, we need to change how we store data to process it more effectively, faster, and cheaper.
The industry trend to adopt computational storage
Snowflake is an excellent example of a product that separates the compute from the storage processing. This results in a perfect opportunity for business leaders to realize the benefits of separating computing from storage. This helps accelerate data read and processing cycle times. The advantage is that users experience faster application and interface responses with faster visualization and presentment of the data requested.
If you’re curious to research additional topics around computational storage, the Storage Networking Industry Association (SNIA) formed a working group in 2018 that has the charge to define vendor-agnostic interoperability standards for computational storage.
As you think about your technology environment and how you’re leveraging and processing data, consider how far your data is from your ability to compute that data and process it analytically. Data needs are growing exponentially, and the demand for computational storage will be tightly coupled to the need to display and visualize organizational data. Your organization might benefit from levering computational storage to connect high-performance computing with traditional storage devices.
Are you curious about business disruption? What are the key drivers of change today, and how are businesses repositioning for a better tomorrow by maximizing growth internally?
Hi, I’m Peter Nichol, Data Science CIO.
Today we’re going to talk about business models and business-model disruption.
New designs for business-model disruption
There are five main principles I want to cover that help define how companies today are driving disruption inside and outside their organizations.
As you read about these principles, I want you to keep this question in mind: “Can I identify and document three different examples for each of these principles?” Do you have clear and documented success stories on these topics? If you do, that’s great—your company’s well on the way to not getting disrupted. However, if you don’t, you’re likely doing lip service to some of these concepts, but you don’t necessarily have these five principles mastered:
Intelligence process automation (IPA)—introduce intelligent automation to reduce human tasks
Lean process design—streamline processes and minimize waste
Business process outsourcing (BPO)—drive the next wave of process outsourcing or offshoring
Advanced analytics—process intelligence to facilitate decisions
Digitization—digitize customer experience and day-to-day operations
Explaining the disruption models
First, we have IPA or intelligent process automation. Essentially, here we’re trying to take the robot out of the human. The automation workflow sits on top of robotic process automation, similar to a system automation orchestration. When the workflow is automated, you free up employees’ time and start to have significant benefits.
The second principle is about streamlining operations. We’re talking about removing the waste using lean manufacturing. When applying Lean Six Sigma concepts to modernize we begin by documenting our business processes to allow us to automate them. If you’ve ever done anything with robotic process automation or intelligent process automation, you realize you can’t automate a process that isn’t documented. Automating a process that isn’t well documented is extremely difficult.
The third principle is business process outsourcing. This concept reevaluates your core business capabilities and identifies which capabilities are supportive or maybe ancillary to your core operations. The helpdesk is a pretty classic example of a capability that’s essential, and you need to make sure you have those supportive IT structures in place. However, being number one in the world in helpdesk servicing won’t create a competitive advantage; it’s not going to be a differentiator. Focus on your core business capabilities and competencies.
The fourth principle is analytics. Digital analytics uses data and information to make new, intelligent decisions. These decisions generate new insights that initially weren’t visible. By visualizing the latest insights, new growth and opportunities are created.
The fifth principle relates to how you manage and orchestrate your business. How does change get rolled out through the organization? Who’s accountable for that change? Who’s on point? As you answer these questions, it’s apparent how many functional leaders have to be involved for change to stick. It’s no wonder that organizational change is so complex, time-consuming, and costly for organizations.
The drivers of change: why change at all?
As we evaluate how change affects organizations, we discover it has three main aspects. We could identify dozens of reasons for change, but they all can be classified and categorized into these three.
Primary drivers of change
Disrupt business
Drive value
Lower operating costs
This is where the business relationship management (BRM) role comes into play. It doesn’t matter if you’re called a business relationship manager, service manager, account supervisor, relationship coordinator, or director. The title doesn’t matter. What’s important is that your organization has a role that provides support and helps different organizations orchestrate and accelerate business adoption and business change. The disruptive business might describe new ideas, a new process, a new business model, or even a new technology business enabler.
Driving value ensures that the strategy is practical. For example, when introducing a new enabling technology or process, is the outcome defined? Driving value helps measure results so they can be rolled up and shared.
Lowering costs is a never-ending battle between leaders and managers. It’s often blown off as not critical until reducing costs is vital and becomes the single organizational priority. A product that’s priced out of the market won’t be viable or competitive.
The critical success factors for not getting disrupted
What company doesn’t want to be nimble? Is there a company out there that wants to be unexpectedly disrupted? I doubt it.
There are two significant factors that determine how susceptible your organization is to disruption:
Your organization has siloed organizational functions.
Your organization focuses on functional accountability, not shared ownership.
Begin by looking at your organizational structure. Is the organizational construct based on the classic functional span of control (operations, development, finance, marketing, etc.)? If you can’t immediately think of the person that owns marketing or finance, it’s a good bet that your organization isn’t positioned well to handle change. Think about cross-functional alignment and designing an accountability model the cuts across the classic functional verticals.
Next, turn your attention to how performance and results are measured. For example, think about the last significant organizational change initiative. How did that roll out through your organization? Were those outcomes shared?
For example, let’s say there’s a new system-modernization initiative. This initiative will require multiple business processes to be remediated and essentially overhauled. How many people would be involved in those discussions? If you’re thinking it will require 20-30 individual leaders, ask yourself, “Is my organization designed to handle change effectively?”
Are individuals involved being measured on the same outcome—e.g., the net adoption of the modernization initiative—or not? If they’re managed based on other metrics related to their function, why are we surprised when their engagement is subpar?
With the removal of silos and the establishment of shared goals, change adoption becomes part of the organizational culture.
How do we hedge against violent and unplanned disruption?
I have a four-step approach to lock in flexibility in your organizational culture. First, make change an essential part of your culture.
Honestly assess your talent.
Link business value to operational capabilities.
Connect customer behavior to value.
Double down on the BRM role.
By focusing on these four areas, you’ll be prepared when change is right around the corner. As you take an honest inventory of your organization’s ability to ebb and flow with today’s dynamic business conditions, ask yourself the following questions. You’ll discover the answer to whether your organization is ready for disruption.
Honestly assess your talent:
Do all the roles exist that are required to advance the company to the next level?
What degree of experience does IT have with our cloud vendors?
Do we have strong enterprise-architecture talent on board today?
Is each role clear about how what they do today maps into the future-state operating model?
Have the costs to acquire talent been recently evaluated?
Is training suggested to employees to accelerate knowledge uptake?
Link business value to operational capabilities:
Is there clear accountability for our multi-cloud strategy?
Is there a defined catalog of standardized IT services?
Has cost been calculated at the service level?
How does governance enable and align organizational capabilities?
Have core capabilities been identified for the department?
Connect customer behavior to value:
Is there a process to explore and fund emerging technologies?
Is IT managing capabilities in addition to unique technologies?
Is technology debt decreasing due to technology modernization?
Is IT proactively presenting solutions to business partners?
Has IT been able to anticipate business needs and discuss, design, and build solutions before they’re required for speed to market and competitive advantages?
Double down on the BRM role:
Do BRMs have a voice in the business strategy?
Are BRMs at least at the director level or above to solidify organizational impact?
Has the term “value” been defined organizationally?
Is the BRM standardized across business units?
Has the organization received training on how to leverage the BRM role?
Has an organizational BRM maturity roadmap been defined, and is it leading to positive outcomes?
Evaluating whether your company is well positioned for change can be highly challenging. Understanding where to discover value and how to validate shared goals can become a real struggle. Start with the financials. If your organization is delivering on investments made, that’s a great indicator that you have the type of change outcomes required and desired. On the other hand, if those investments aren’t being realized, it probably warrants reflection to design an organization ready to change.
Are you trying to deliver more functionality into production at a faster cadence? Are users asking your team to prioritize time-to-market over quality? Do you have release cycles longer than 3-4 days? Do you constantly review and prioritize issues that continue to resurface?
You might be in a great position to benefit from DevOps.
Hi, I’m Peter Nichol, Data Science CIO.
DevOps integrates the development and operations activity of the software development process to shorten development cycles and increase deployment frequency. DevOps centers around a handful of critical principles. If you’re ever unclear about how DevOps might apply, bring yourself back to the fundamental principles. This helps to drive the intent behind the outcomes achieved by adopting and implementing DevOps.
Continuous improvement: introducing a steady pace of improvements to existing models
Lean practices: improving efficiency and effectiveness by eliminating process waste
System-oriented approaches: focusing on conditions required for maximum system effectiveness
Focus on people and culture: optimizing people and inspiring culture to drive positive outcomes
Collaboration (development and operations teams): establishing a shared vision and shared goals to enable inclusion
DevOps automates interactions that otherwise might result in unplanned delays or bottlenecks.
What is DevOps, and where did it originate?
Today, we’re going to talk about DevOps—development operations. DevOps embraces the idea of automated collaborations to develop and deploy software.
The term “DevOps” was coined in 2009 by Patrick Dubois, the father of DevOps. DevOps is a combination of development and operations. It’s a kind of classic example of yin and yang:
Developers want change
Operations want stability
Combining development and operations sounds simple enough, but what elements make up development and operations? Let’s take a minute to define these terms clearly.
Development includes:
Software development
Build, compile, integrate
Quality assurance
Software release
Support of deployment and production tasks as needed
Operations includes:
System administration
Provisioning and configuration
Health and performance monitoring of servers, critical software infrastructure, and applications
Change and release management
infrastructure orchestration
What problem does DevOps solve?
Developers typically want to release more code into production, enabling increased user functionality. This results in an environment of constant change and often questionable stability. Meanwhile, operations is focused on stability and less so on changes. Operations wants to establish a stable and durable base for operational effects; i.e., supporting production-grade and commercial applications that don’t fare well with constant changes.
The conflicting objectives between development and operations create polarization of the team. This polarization creates a natural conflict. DevOps attempts to bridge this gap through automation and collaboration.
DevOps connects your development operations teams to generate new functionality while maintaining existing or commercial functionality in production. DevOps primarily has three goals that are targeted either when it’s first introduced into an organization or after an internal DevOps optimization.
DevOps goals:
Continuous value delivery
Reduction in cycle time
Improved speeds to market
Value delivery validates that what’s developed is useful and has business adoption. Cycle-time reductions go hand in hand with an increase in deployment frequency. Lastly, speed to market looks at the demand intake process and reduces the time from the initial request to when usable functionality is available in production. These combined benefits drive the majority of use cases in support of DevOps.
DevOps benefits
The more time you spend exploring the benefits of DevOps, the more obvious how expansive the benefits derived from implementing and adopting DevOps are. Below I’ve listed several benefits; however, let me first expand on a few of my favorites:
Continuous value delivery: as we automate these different processes through the development and operations lifecycle, we remove waste and provide the ability to achieve continuous value.
Faster orchestration through the pipeline: once we start to automate, we reduce the manual handoffs. As a result, that functionality moves through, gets tested, and gets put into production much faster.
Reduced cycle times: as we put functionality into production and automate it, the time it takes from start to finish begins to decrease. This results in the perception of increased value or a faster cadence of the value we can provide.
Here are some additional and expected benefits of adopting DevOps principles:
Benefits of DevOps
Continuous software delivery
Faster detection and resolution of issues
Reduced complexity
Satisfied and more productive teams
Higher employee engagement
Greater development opportunities
Faster delivery of innovation
More stable operating environments
Improved communication and collaboration
How do we measure success?
It sounds like DevOps has benefits. That’s great. But how do we measure the success of DevOps efforts? Entire books have been written on this topic. There’s no lack of knowledge available that’s been published and even posted on the Internet. However, I boil down measuring DevOps success into three buckets:
Performance
Quality
Speed
By starting with these anchors for managing success, you’re sure to have a simple model to communicate to your leadership. Although there are hundreds of other metrics, I find these to be the most effective when presenting quantified outcomes of DevOps implementations and adoptions.
Performance
Uptime
Resource utilization
Response time
Quality
Success rate
Crash rate
Open/close rates
Speed
Lead time
Cycle time
Frequency of release
Putting DevOps into action
We covered what DevOps is, where it originated, the problem it solves, the benefits, and how to measure success. Now we’re ready to discuss how to put DevOps into action. This begins by understanding the DevOps lifecycle:
Build
Test
Deploy
Run
Monitor
Manage
Notify
I’ll expand on products that are used across each phase. However, to do that, I’m going to simplify the lifecycle steps into three phases:
Develop and test: continuous testing
Release and deploy: short release cycles
Monitor and optimize: improved product efficiency
Here are best-in-class products that are commonly found in a DevOps pipeline:
Develop and test – continuous testing
Confluence
AccuRev
JUnit
IBM Rational
Fortify
Visual Studio
VectorCast
Release and deploy – shorter release cycles
ServiceNow
Maven
Artifactory
NAnt
Jenkins
Bamboo
Monitor and optimize – improved product efficiency
Zabbix
Graphite
Nagios
QA Complete
VersionOne
New Relic
When we think about the aspects of DevOps, we quickly land on what type of tools we can introduce into these environments.
Build: Jira, GRUNT (Bamboo plugins), Bamboo SBT, Gradle, and Jenkins
Test: Visual Studio, TestLink, TestRail, Jenkins, LoadImpact, and JMeter
We also have DevOps tools like Jenkins, Chef, Puppet, and others that provide workflow and workflow automation.
A quick DevOps example
Many of my LinkedIn followers asked for a practical example of how DevOps is leveraged in the wild. Enjoy.
Situation: A new data-science and advanced-analytics team was recently launched that focuses on data literacy to allow access to data that must be validated and published. However, data stewards are reporting data publishing is taking too long and resulting in reporting on old data sets. The opportunity is to get data into the hands of power users (scientists, bioinformatics, and the data community) more quickly. Today, users are reporting slowness in data availability.
Complication: The data isn’t being ingested from a single source. In fact, because of the intelligence generated from the data sourcing, the timing of sources varies based on data timeliness. The team is leveraging a data lake to capture data relating to patient longitudinal, claims, EHR, EMR, and sales data such as IQVIA, Veeva CRM, SalesForce Marketing Cloud (SFMC) that includes promotional activities, general marketing, and financial data.
Resolution: The team developed an entire automation workflow in Jenkins. This resulted in a 42% improvement in data timeliness. Data was refreshed every four days, not every seven days.
Here’s the general approach that was taken to achieve the results:
Develop + build + test
Daily scrum – maximum of 15 minutes where each team member can share updates
Sprint review
Daily/weekly status updates to client
Automated tasks to cover:
Build management
Automated unit testing
QA environment configuration
Code completion
Code freeze
Regression testing on preview/stage environment before going live
Go live
DevOps offers opportunities to get to market faster, decrease cycle times, and ultimately get functionality to your business users more quickly. Decrease your dependence on manual processes and introduce DevOps throughout your delivery pipeline.
Have you ever been told to improve but weren’t sure what to work on? Have you asked your team to do better and improve their performance—and then, a week later, the group wants to have a discussion about precisely what that means?
Hi, I’m Peter Nichol, Data Science CIO.
What is Team Point?
Today, we’re going to talk about a concept I created called Team Point. Team Point is an approach for providing individuals and teams with a quantifiable baseline for performance.
If you’re a team leader and are charged with improving that team, this approach is enormously powerful. The beauty of Team Point is that it offers a method to measure the team’s progress toward a quantifiable objective. No longer will you be introducing techniques and not be able to link them to performance. From now on, every best practice you implement can be measured and quantified to determine your team’s positive (or negative) effect.
What problem are we solving?
Have you ever taken ownership of a new team or joined a new organization? Initially, the role sounded straightforward. Then, you heard rumors of the team not delivering. Stakeholders were getting increasingly frustrated because quality varied from product to product and manager to manager. You’ve started to get more requests for named individuals, resulting in some staff being overallocated and others being under-allocated.
When everything is on fire, where do you start? These fires pop up almost everywhere:
Deliverables are being missed.
Issues aren’t communicated.
Risks aren’t escalated in a timely fashion.
Critical milestones are delayed, resulting in additional escalations.
Project meetings have conflicting agendas.
Stakeholders want team members removed.
When everything is on fire, one thing is for sure—you can’t be running from hot spot to hot spot. That doesn’t work. Here’s what does work.
Choose a framework for evaluation
This hot environment requires an organized and systematic approach. Team Point works by applying an evaluation method of, “show me, don’t tell me.”
It’s essential to choose a framework and identify categories that accurately represent the areas of competency that you’re interested in evaluating. This will vary depending on the role, industry, and domain. I’ll share what I use for project and program management areas to demonstrate competency. I’ve found that these categories—originated from a previous PMI PMBOK version—work exceptionally well to capture the significant elements of project management competence.
Project Management
Integration management
Scope management
Time management
Cost management
Quality management
Human Resource management
Risk management
Procurement management
Stakeholder management
Communication management
I’ve adjusted some of the competence areas for program managers to make them more strategic and outcome-focused in nature.
Program Management
Program portfolio management
Strategy and investment funding
Program governance
Program management financial performance
Portfolio metrics and quality management
Program human capital management
Program value and risk management
Program contract management
Program stakeholder engagement
Communication management
The PMI PMBOK 7th edition was released on August 1, 2021. There are valuable pieces that leaders may want to pull from this text. I’ve referenced the eight most functional performance domains:
Performance Domains (PMBOK 7th edition)
Stakeholders: interactions and relationships
Team: high performance
Development approach and lifecycle: appropriate development approach, planning, organizing, elaborating, and coordinated work
Project work: enabling the team to deliver
Delivery: strategy execution, advancing business objectives, delivery of intended outcomes
Uncertainty: activities and functions associated with risks and uncertainty
Measurement: acceptable performance
It’s critical to select areas of competency that resonate with your executive leadership. Don’t feel you have to use conventional categories. Much of the value of this framework comes from experienced leaders tailoring the areas of competency to their business purpose and desired outcomes.
Identify questions to demonstrate competency
The majority of questions I receive about Team Point is how to administer the approach in a real setting. So, I’ll share a specific example of how this works and why the system is uniquely impactful.
No one wants to be told how to think. The close follow-up to this is, managers always have unique or creative ways of operating that they’ve matured over the years. Some of these techniques are unusual but effective, while others have deteriorated over time. Here are a few examples in practice.
Contact Lists
First—in this case—I sit down with the project manager and ask about how they manage the contacts for the project. The trick is, there’s no “right” answer here, but there are wrong answers. The tool they use to track contacts doesn’t matter. I’m also not checking for the frequency of how often that list is updated. The project manager will either produce a contact list or say why it matters that I know who to contact.
In this case, I’ll pose a question: “You’re on PTO (paid time off), and the business analyst on your project wants to contact the tech lead. Where do they go to find that information?” It’s clear how inefficient communication will be if those business analysts have nothing to reference.
If the project manager is organized, they might have a contact list documented in Confluence. The project manager could have a project list included in a project charter. There may be a SharePoint library with contacts listed. Each of these is a reasonable solution. The goal is to create a reasonable approach for the business analyst to get to that information. Often, I’ll hear something like, “Well, everyone knows how to find that contact information, even if it’s not documented.” I’ll usually reply with, “If we text, Michelle, your business analyst, now, she’ll know how to find the database lead’s cell phone number, right?”
The value here is asking the project manager to show me—not tell me—where the information is located. I’ll have the project manager do a screen share and navigate where the business analyst would find relevant contact information.
If the project manager can’t find the information in five to 10 seconds, it’s a pretty good bet the business analyst would have no idea where to find that contact information.
How does Team Point change behavior?
As leaders gather more experience, they can articulate situations more clearly—even when they aren’t all that clear. A good example is our contact list question. It’s easy to explain how the information would be shared among team members. However, it’s much harder to demonstrate how to set up and execute that process to achieve the desired outcome effectively.
So, how does Team Point change behavior? It measures what matters.
We’re defining the standard upon which each individual and every team member will be measured. Most teams have goals, but ask for clarification of the goal there is no supporting detail. It’s simply a vast wasteland of assumptions.
This is where we add clarity—because being measured against a standard that isn’t defined sucks. It’s also not fair to your team. The standard for good performance should be visible and transparent to everyone on the team. There’s no grey performance in this model. You’re either above the line or below the line.
Using gamification to drive desired outcomes
If there’s not a clear standard for good performance, the team operates in this fuzzy state. They make some effort but never exert all their energy because the objective isn’t clear.
Do you need a contact list? Do you need an architecture plan? Do you need to schedule weekly meetings? The project manager can guess but doesn’t know for sure. Maybe they should know, but perhaps they shouldn’t.
This model defines behavior that’s expected 100% of the time. There is no longer any question about what’s expected. Of course, based on the size of projects, some models require more artifacts or less, but what’s relevant here is, even then, what’s expected is clear. There’s no grey.
Every team member knows their unique score based on their demonstrated competency, and they also know how they’d rate the entire team. This creates healthy competition among team members without adding undo team friction.
How to implement Team Point
Our goal is to provide individuals and teams with a quantifiable baseline for performance. To administer the evaluation, the same questions need to be asked of each individual in a similar role. For example, all project managers should have the same (or a very similar) set of questions. The same logic applies to program managers. Therefore, all program managers should receive the same questions. This ensures that results can be aggregated and rolled up smoothly.
Here’s how you start to roll out Team Point for your group:
Choose categories for evaluation
Identify your questions related to each category
Determine acceptable answers
Conduct the Team Point assessment
Report individual and team results
You want managers to think, so, explain what you’re looking for, not how to produce those results. For almost every question, there are multiple approaches to the answer that are acceptable.
How to measure and report results
There are two levels of reporting results: individual and team.
The individual results are specific to that resource and address their areas of strength and weakness. The team results show rolled-up performance and represent the directional performance of the team.
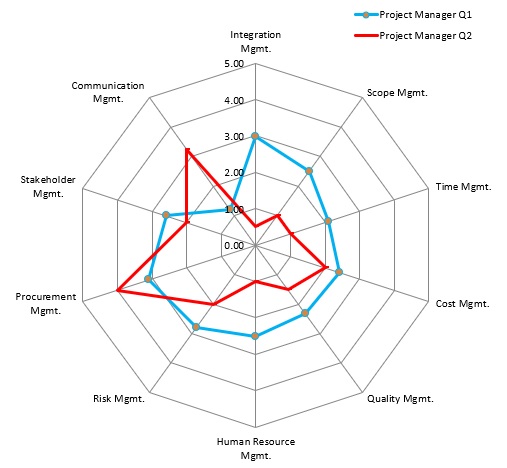
Illustration 1.0 Individual Performance
Individual performance is always accompanied by detailed explanations of how the individual performed compared to the team, on average. This helps an individual understand precisely how they’re performing in relation to their peers. While the below percentages in the below example don’t represent the graphic above, when distributing individual results, the graph and the percentages would match.
Integration management: 33% vs. 55%
Scope management: 78% vs. 45%
Time management: 78% vs. 32%
Cost management: 78% vs. 76%
Quality management:. 43% vs. 11%
Human Resource management: 44% vs. 33%
Risk management: 87% vs. 51%
Procurement management: 51% vs. 42%
Stakeholder management: 86% vs. 67%
Communication management: 13% vs. 23%
Team Point is powerful in that you’re able to show individual performance charted over team performance. So, for example, you’d compare Q1 versus Q2 performance of a particular project manager.
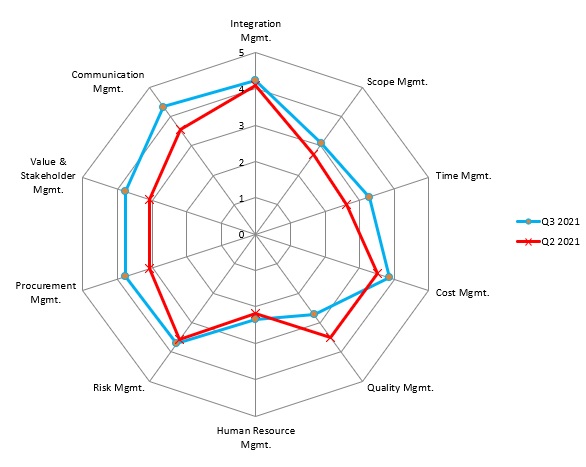
Illustration 2.0 Team Performance
You’d also report team performance quarter over quarter. This helps to illustrate directional progress and precisely measures any best practices or elements you, as a leader, introduced that might improve team results.
This gives resources a view of where they are individually, how they rank against the team as a percentage of effectiveness, and where they are compared to the previous quarter.
Why it’s so powerful
This model translates soft activities into complex outcomes. For example, let’s assume that, over the quarter, you made some adjustments to the team:
The lifecycle steps were reduced.
The team was retrained on financial management.
Maintenance of artifact documentation was transitioned to a project coordinator.
An intern model was introduced, and two new interns are assisting senior-level project managers.
The project management meeting structure was optimized.
How do you measure any of these benefits? It’s possible, of course, but it’s extremely challenging. Using Team Point, you can link the best practices you implemented to a demonstrated competency model that can be quantified.
Hopefully, these insights offer a new perspective on using Team Point to precisely pinpoint where your team needs to improve and, similarly, where they’re performing strongly.
If you don’t subscribe to my newsletter, please do so at newsletter dot data science CIO dot com. I share insights every week to a select group of individuals on new concepts in innovation and digital transformation that I’ve been made aware of and love to share.
How are you leveraging automation in your organization today? Which parts of the company are optimizing artificial intelligence to enable a better customer experience?
Hi, I’m Peter Nichol, Data Science CIO.
Today, we’ll talk about natural language processing (NLP) and how it can help accelerate technology adoption in your organization.
Neuro-linguistic programming (influencing value, beliefs, and behavior change) and natural language processing (helping humans better interact with machines or robots) are separate concepts, both of which are identified by the NLP acronym. Make sure you’re clear about which one you’re talking about.
Again, today we’ll be discussing natural language processing.
What is NLP?
NLP is the combination of linguistics and computer science.
Essentially, NLP helps computers better understand what we humans are trying to say. The application of NLP makes it feasible for us to digest, test, and interpret language; measure sentiment; and, ultimately, understand what exactly we mean behind what we’re saying. NLP incorporates a dynamic set of rules and structures that enable computers to accurately interpret what’s said or written (speech and text).
How is NLP being leveraged?
There are many ways in which we see NLP being adopted by organizations. First, we have chatbots and other customer-based tools that allow consumers to interface and interact with technology. In more simplistic terms, the application of NLP helps computers recognize patterns and interpret phraseology to understand what we, as humans, are attempting to do. There are many great examples of NLP in use today; here are a few of my favorites:
Siri and Google assistance
Spam filtering
Grammar and error checking
Siri translates what you say into what you’re looking for by utilizing speech recognition (translation speed) and natural language processing (interpretation of a text). So, for example, NLP can understand your unique voice timbre and accent and then translate this into what you’re trying to say. Google Assistant is another excellent example of speech recognition and natural language process working in tandem.
Spam filtering uses NLP to interpret the type of outcome expressed and recognizing patterns of expression and through processes in the text. In this way, spam filtering uses NLP to determine if the message you received was sent from a friend or from a marketing company.
Grammar-error checking is an excellent use of NLP and super helpful. NLP references a massive database of words and phrases compiled from these use cases and compares what’s entered with that database to determine if a pattern has been used previously.
Text classification looks at your email and makes judgments based on text interpretation. If you’ve ever paid attention to your Gmail, you might have noticed your email is categorized in several ways. For example, you’ll have your primary email in one folder, and you’ll have spam and promotional emails in another. Unfortunately, you didn’t make the delineations; an NLP agent did.
NLP is behind all that type of stuff. It’s artificial intelligence. Essentially, it’s looking at what you say, what text is being written, and interpreting what you mean. As NLP adoption grows and is brought into mainstream business software, we realize there’s much potential to leverage NLP in our environments. The potential of NLP is powerful, especially when we begin to focus on automation and, ultimately, data or technology adoption.
NLP’s role in data democratization
Focusing on data democratization is an excellent example of how NLP can make its mark. Many CIOs and leaders are building data-driven cultures and striving to help raise the data awareness of employees about how to leverage and optimize data, provide insights, and determine and interpret analytics from more extensive data sources. But that’s not always possible.
A lot of the data we use—whether social media or other types of generic input, even voice—is unstructured. It doesn’t fit in well with traditional databases comprising columns and rows. This data is unstructured and, as a result, we need different ways to interpret it.
Historically, we needed particular individuals that could interpret and understand how that unstructured data could be aggregated, cleansed, and, finally, provided to consumers. Today, with data democratization, we’re trying to access tools and technologies that make interpretation fast and seamless. In addition, data democratization attempts to get everyone in the organization comfortable with working with data to make data-informed decisions.
Why does data democratization matter when building a data-driven culture? First, a significant part of building a data-driven culture is offering greater access to the data. This means individuals who otherwise might not have access to that data set can now execute queries, gather correlations, and generate new insights.
The first step toward building that data-driven culture is ensuring that you’ve captured intelligent and valuable data. Next, consider adding additional automation into your ecosystem and explore new ways to work with your business applications.
NLP has the potential to accelerate your most critical initiatives. Take time today to discover which of your approved initiatives could benefit from NLP.